Difference between revisions of "Manuals/calci/HYPGEOMDIST"
Jump to navigation
Jump to search
| Line 1: | Line 1: | ||
| − | + | <div style="font-size:30px">'''HYPGEOMDIST(n1,n2,n3,n4)'''</div><br/> | |
*<math>n1</math> is the sample's success. | *<math>n1</math> is the sample's success. | ||
*<math>n2</math> is the sample's size. | *<math>n2</math> is the sample's size. | ||
| − | *<math>n3</math> is population's success | + | *<math>n3</math> is population's success. |
*<math>n4</math> is the population size. | *<math>n4</math> is the population size. | ||
| + | |||
==Description== | ==Description== | ||
| − | + | *This function gives the result of Hypergeometric distribution. | |
| − | This distribution is a discrete probability distribution which is contrast to the binomial distribution. | + | *This distribution is a discrete probability distribution which is contrast to the binomial distribution. |
| − | A hypergeometric random variable is the number of successes that result from a hypergeometric experiment. | + | *A hypergeometric random variable is the number of successes that result from a hypergeometric experiment. |
| − | The probability distribution of a hypergeometric random variable is called a hypergeometric distribution. | + | *The probability distribution of a hypergeometric random variable is called a hypergeometric distribution. |
| − | In HYPGEOMDIST(n1,n2,n3,n4) where n1 is thenumber of items in the Sample that are classified as successes. | + | *In HYPGEOMDIST(n1,n2,n3,n4) where n1 is thenumber of items in the Sample that are classified as successes. |
| − | n2 is the total number of items in the sample. | + | *n2 is the total number of items in the sample. |
| − | n3 is thenumber of items in the population that are classified as successes and n4 is the total number of items in the sample. | + | *n3 is thenumber of items in the population that are classified as successes and n4 is the total number of items in the sample. |
| − | The following conditions are applied to the Hypergeometric distribution: | + | *The following conditions are applied to the Hypergeometric distribution: |
| − | + | #This distribution is applies to sampling without replacement from a finite population whose elements can be classified into two categories like success or Failure. | |
| − | + | #The population or set to be sampled consists of N individuals, objects,or elements | |
| − | + | #Each individual can be success (S) or a failure (F), | |
and there areM successes in the population. | and there areM successes in the population. | ||
| − | + | #A sample of n individuals is selected without replacement in such a way that each subset of size n is equally likely to be chosen. The Hyper geometric probability distribution is: | |
P(X=x)=h(x;n,M,N)=(M (N-M | P(X=x)=h(x;n,M,N)=(M (N-M | ||
x) n-x) /(N | x) n-x) /(N | ||
| − | n) for x is an integer satisfying max(0, n-N+M)<=x<=min(n,M). where x is sample's success.n is the sample's size.M is population's success and N is the population size. Here we can give any positive real numbers. Suppose we are assigning any decimals numbers it will change in to Integers. This function will give result as error when | + | n) for x is an integer satisfying max(0, n-N+M)<=x<=min(n,M). where x is sample's success. |
| − | + | *n is the sample's size. | |
| − | + | *M is population's success and N is the population size. | |
| − | + | *Here we can give any positive real numbers. | |
| − | + | *Suppose we are assigning any decimals numbers it will change in to Integers. | |
| − | + | *This function will give result as error when | |
| − | + | #Any one of the argument is nonnumeric. | |
| − | + | #n1<0 or n1 is greater than the smaller value of n2 or n3. | |
| − | + | #n1 is less than the bigger of 0 or(n2-n4+n3) | |
| − | + | #n2<=0 or n2>n4 | |
| − | + | #n3<=0 or n3>n4 or n4<=0" | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
==Examples== | ==Examples== | ||
| − | # | + | #HARMEAN(1,2,3,4,5)=2.18978102189781 |
| − | + | #HARMEAN(20,25,32,41)=27.4649361523969 | |
| − | # | + | #HARMEAN(0.25,5.4,3.7,10.1,15.2)=1.0821913906985883 |
| − | + | #HARMEAN(3,5,0,2)=NAN | |
| − | # | + | #HARMEAN(1,-2,4)=NAN |
| − | |||
==See Also== | ==See Also== | ||
| − | *[[Manuals/calci/ | + | *[[Manuals/calci/AVERAGE | AVERAGE ]] |
| − | *[[Manuals/calci/ | + | *[[Manuals/calci/GEOMEAN | GEOMEAN ]] |
==References== | ==References== | ||
[http://en.wikipedia.org/wiki/Pearson_product-moment_correlation_coefficient| Correlation] | [http://en.wikipedia.org/wiki/Pearson_product-moment_correlation_coefficient| Correlation] | ||
Revision as of 01:41, 10 December 2013
HYPGEOMDIST(n1,n2,n3,n4)
- is the sample's success.
- is the sample's size.
- is population's success.
- is the population size.
 is the sample's success.
is the sample's success.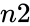 is the sample's size.
is the sample's size.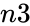 is population's success.
is population's success.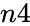 is the population size.
is the population size.Description
- This function gives the result of Hypergeometric distribution.
- This distribution is a discrete probability distribution which is contrast to the binomial distribution.
- A hypergeometric random variable is the number of successes that result from a hypergeometric experiment.
- The probability distribution of a hypergeometric random variable is called a hypergeometric distribution.
- In HYPGEOMDIST(n1,n2,n3,n4) where n1 is thenumber of items in the Sample that are classified as successes.
- n2 is the total number of items in the sample.
- n3 is thenumber of items in the population that are classified as successes and n4 is the total number of items in the sample.
- The following conditions are applied to the Hypergeometric distribution:
- This distribution is applies to sampling without replacement from a finite population whose elements can be classified into two categories like success or Failure.
- The population or set to be sampled consists of N individuals, objects,or elements
- Each individual can be success (S) or a failure (F),
and there areM successes in the population.
- A sample of n individuals is selected without replacement in such a way that each subset of size n is equally likely to be chosen. The Hyper geometric probability distribution is:
P(X=x)=h(x;n,M,N)=(M (N-M
x) n-x) /(N
n) for x is an integer satisfying max(0, n-N+M)<=x<=min(n,M). where x is sample's success.
- n is the sample's size.
- M is population's success and N is the population size.
- Here we can give any positive real numbers.
- Suppose we are assigning any decimals numbers it will change in to Integers.
- This function will give result as error when
- Any one of the argument is nonnumeric.
- n1<0 or n1 is greater than the smaller value of n2 or n3.
- n1 is less than the bigger of 0 or(n2-n4+n3)
- n2<=0 or n2>n4
- n3<=0 or n3>n4 or n4<=0"
Examples
- HARMEAN(1,2,3,4,5)=2.18978102189781
- HARMEAN(20,25,32,41)=27.4649361523969
- HARMEAN(0.25,5.4,3.7,10.1,15.2)=1.0821913906985883
- HARMEAN(3,5,0,2)=NAN
- HARMEAN(1,-2,4)=NAN
See Also