Difference between revisions of "Manuals/calci/REGRESSIONANALYSIS"
Jump to navigation
Jump to search
(Created page with "regreession") |
|||
| Line 1: | Line 1: | ||
| − | + | <div style="font-size:30px">'''REGRESSIONANALYSIS (YRange,XRange,ConfidenceLevel,NewTableFlag)'''</div><br/> | |
| + | *<math>YRange </math> is the set of dependent variables . | ||
| + | *<math>XRange </math> is the set of independent variables. | ||
| + | *<math>ConfidenceLevel</math> level of Confidence value. | ||
| + | *<math>NewTableFlag </math> is either 0 or 1. | ||
| + | |||
| + | ==Description== | ||
| + | *This function is calculating the Regression analysis of the given data. | ||
| + | *This analysis is very useful for the analyzing the large amounts of data and making predictions. | ||
| + | *Regression analysis is a form of predictive modelling technique which investigates the relationship between a dependent and independent variable. | ||
| + | *This technique is used for forecasting, time series modelling and finding the causal effect relationship between the variables. | ||
| + | *This analysis give the result in three table values. | ||
| + | # Regression statistics table. | ||
| + | # ANOVA table. | ||
| + | # Residual output. | ||
| + | 1.'''Regression statistics''' : | ||
| + | *It contains multiple R, R Square, Adjusted R Square, Standard Error and observations. | ||
| + | *R square gives the fitness of the data with the regression line. | ||
| + | *That value is closer to 1 is the better the regression line fits the data. | ||
| + | *Standard Error refers to the estimated standard deviation of the error term. It is called the standard error of the regression. | ||
| + | 2.'''ANOVA table''': | ||
| + | *ANOVA is the analysis of variance. | ||
| + | *This table splits in to two components which is Residual and Regression. | ||
| + | Total sum of squares = Residual (error) sum of squares + Regression (explained) sum of squares. | ||
| + | *Also this table gives the probability, T stat, significance of F and P. | ||
| + | *When the significance of F is < 0.05, then the result for the given data is statistically significant. | ||
| + | *When the significance of F is > 0.05, then better to stop using this set of independent variables. | ||
| + | *Then remove a variable with a high P-value and return the regression until Significance F drops below 0.05. | ||
| + | *So the Significance of P value should be <0.05. | ||
| + | *This table containing the regression coefficient values also. | ||
| + | 3.'''Residual output''': | ||
| + | *The residuals show you how far away the actual data points are from the predicted data points. | ||
Revision as of 15:20, 20 December 2016
REGRESSIONANALYSIS (YRange,XRange,ConfidenceLevel,NewTableFlag)
- is the set of dependent variables .
- is the set of independent variables.
- level of Confidence value.
- is either 0 or 1.
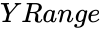 is the set of dependent variables .
is the set of dependent variables .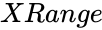 is the set of independent variables.
is the set of independent variables.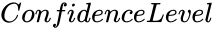 level of Confidence value.
level of Confidence value.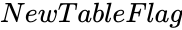 is either 0 or 1.
is either 0 or 1.Description
- This function is calculating the Regression analysis of the given data.
- This analysis is very useful for the analyzing the large amounts of data and making predictions.
- Regression analysis is a form of predictive modelling technique which investigates the relationship between a dependent and independent variable.
- This technique is used for forecasting, time series modelling and finding the causal effect relationship between the variables.
- This analysis give the result in three table values.
- Regression statistics table.
- ANOVA table.
- Residual output.
1.Regression statistics :
- It contains multiple R, R Square, Adjusted R Square, Standard Error and observations.
- R square gives the fitness of the data with the regression line.
- That value is closer to 1 is the better the regression line fits the data.
- Standard Error refers to the estimated standard deviation of the error term. It is called the standard error of the regression.
2.ANOVA table:
- ANOVA is the analysis of variance.
- This table splits in to two components which is Residual and Regression.
Total sum of squares = Residual (error) sum of squares + Regression (explained) sum of squares.
- Also this table gives the probability, T stat, significance of F and P.
- When the significance of F is < 0.05, then the result for the given data is statistically significant.
- When the significance of F is > 0.05, then better to stop using this set of independent variables.
- Then remove a variable with a high P-value and return the regression until Significance F drops below 0.05.
- So the Significance of P value should be <0.05.
- This table containing the regression coefficient values also.
3.Residual output:
- The residuals show you how far away the actual data points are from the predicted data points.