Difference between revisions of "Manuals/calci/KSTESTNORMAL"
Jump to navigation
Jump to search
| (7 intermediate revisions by 3 users not shown) | |||
| Line 1: | Line 1: | ||
| − | <div style="font-size:25px">'''KSTESTNORMAL(XRange,ObservedFrequency, | + | <div style="font-size:25px">'''KSTESTNORMAL (XRange,ObservedFrequency,Confidence,DoMidPointOfIntervals,NewTableFlag)'''</div><br/> |
| − | *<math> | + | *<math>XRange</math> is the array of x values. |
*<math>ObservedFrequency</math> is the frequency of values to test. | *<math>ObservedFrequency</math> is the frequency of values to test. | ||
| − | *<math> | + | *<math>Confidence</math> is the mean Value. |
| − | *<math> | + | *<math>DoMidPointOfIntervals</math> is the standard deviation of the set of values. |
| − | *<math> | + | *<math>NewTableFlag</math> is either TRUE or FALSE. |
| − | |||
==Description== | ==Description== | ||
| Line 25: | Line 24: | ||
*3.Largest empirical estimate of fraction of points falling below <math>x_i</math> and computed as <math>\frac{i}{n}</math> for i=1,...,n. | *3.Largest empirical estimate of fraction of points falling below <math>x_i</math> and computed as <math>\frac{i}{n}</math> for i=1,...,n. | ||
*4.Theoretical estimate of fraction of points falling below <math>x_i</math> and computed as <math>F(x_i)</math>, where F(x) is the theoretical distribution function being tested. | *4.Theoretical estimate of fraction of points falling below <math>x_i</math> and computed as <math>F(x_i)</math>, where F(x) is the theoretical distribution function being tested. | ||
| − | 5.Find the absolute value of difference of Smallest and largest empirical value with the theoretical estimation of points. | + | *5.Find the absolute value of difference of Smallest and largest empirical value with the theoretical estimation of points. |
*This is a measure of "error" for this data point. | *This is a measure of "error" for this data point. | ||
*6.From the largest error, we can compute the test statistic. | *6.From the largest error, we can compute the test statistic. | ||
| − | *The Kolmogorov-Smirnov test statistic for the cumulative distribution F(x) is:<math> D_n=Sup_x|F_n(x)-F(x)|</math> | + | *The Kolmogorov-Smirnov test statistic for the cumulative distribution F(x) is:<math> D_n=Sup_x|F_n(x)-F(x)|</math>where <math>sup_x</math> is the supremum of the set of distances. |
| − | *<math>F_n(x)</math> is the empirical distribution function for n,with the observations <math>X_i</math> is defined as:<math>F_n(x)=\frac{1}{n}\sum_{i=1}^n I_{X_i\le x}</math> | + | *<math>F_n(x)</math> is the empirical distribution function for n,with the observations <math>X_i</math> is defined as:<math>F_n(x)=\frac{1}{n}\sum_{i=1}^n I_{X_i\le x}</math>where <math>I_{X_i\le x}</math> is the indicator function, equal to 1 if <math>X_i\le x</math> and equal to 0 otherwise. |
| + | |||
| + | ==Example== | ||
| + | {| class="wikitable" | ||
| + | |+Spreadsheet | ||
| + | |- | ||
| + | ! !! A !! B | ||
| + | |- | ||
| + | ! 1 | ||
| + | | 15 || 20 | ||
| + | |- | ||
| + | ! 2 | ||
| + | | 17 || 14 | ||
| + | |- | ||
| + | ! 3 | ||
| + | | 19 || 16 | ||
| + | |- | ||
| + | ! 4 | ||
| + | | 21 || 25 | ||
| + | |- | ||
| + | !5 | ||
| + | | 23 || 27 | ||
| + | |} | ||
| + | *=KSTESTNORMAL(A1:A5,B1:B5,19,3.16) | ||
| + | {| class="wikitable" | ||
| + | |+KOLMOGOROV-SMIRNOV TEST | ||
| + | |- | ||
| + | !DATA!!OBSERVED FREQUENCY!!CUMULATIVE OBSERVED FREQUENCY !!SN!!Z-SCORE!!F(X)!!DIFFERENCE | ||
| + | |- | ||
| + | |15||20||20||0.19608||-0.74915||0.22688||0.03081 | ||
| + | |- | ||
| + | |17||14||34||0.33333||-0.07293||0.47093||0.1376 | ||
| + | |- | ||
| + | |19||16||50||0.4902||0.6033||0.72684|| 0.23665 | ||
| + | |- | ||
| + | |21||25||75||0.73529||1.27952|| 0.89964||0.16435 | ||
| + | |- | ||
| + | |23||27||102||1 ||1.95574||0.97475||0.02525 | ||
| + | |} | ||
| + | {| class="wikitable" | ||
| + | |+TEST STATISTICS | ||
| + | !ANALYSIS | ||
| + | |- | ||
| + | |MEAN|| 17.21569 | ||
| + | |- | ||
| + | |STANDARDDEVIATION || 2.95761 | ||
| + | |- | ||
| + | |COUNT ||5 | ||
| + | |- | ||
| + | |D || 0.23665 | ||
| + | |- | ||
| + | |D-CRITICAL|| #ERROR | ||
| + | |} | ||
| + | |||
| + | '''KS TEST''' | ||
| + | ''TYPE NORMALDIST'' | ||
| + | *CONCLUSION - THE DATA IS NOT A GOOD FIT WITH THE DISTRIBUTION. | ||
| + | |||
| + | ==Related Videos== | ||
| + | |||
| + | {{#ev:youtube|9Of2LTy5Sq0|280|center|K-S Test}} | ||
| + | |||
| + | ==See Also== | ||
| + | *[[Manuals/calci/LEVENESTEST| LEVENESTEST]] | ||
| + | *[[Manuals/calci/MOODSMEDIANTEST| MOODSMEDIANTEST]] | ||
| + | *[[Manuals/calci/RIEMANNZETA| RIEMANNZETA]] | ||
| + | *[[Manuals/calci/MANNWHITNEYUTEST| MANNWHITNEYUTEST]] | ||
| + | |||
| + | ==References== | ||
| + | *[http://www.itl.nist.gov/div898/handbook/eda/section3/eda35g.htm Kolmogorov-Smirnov Goodness of Fit test] | ||
| + | |||
| + | |||
| + | |||
| + | *[[Z_API_Functions | List of Main Z Functions]] | ||
| + | |||
| + | *[[ Z3 | Z3 home ]] | ||
Latest revision as of 15:50, 14 June 2018
KSTESTNORMAL (XRange,ObservedFrequency,Confidence,DoMidPointOfIntervals,NewTableFlag)
- is the array of x values.
- is the frequency of values to test.
- is the mean Value.
- is the standard deviation of the set of values.
- is either TRUE or FALSE.
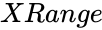 is the array of x values.
is the array of x values.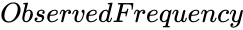 is the frequency of values to test.
is the frequency of values to test.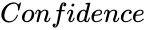 is the mean Value.
is the mean Value.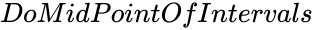 is the standard deviation of the set of values.
is the standard deviation of the set of values.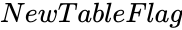 is either TRUE or FALSE.
is either TRUE or FALSE.Description
- This function gives the test statistic of the K-S test.
- K-S test is indicating the Kolmogorov-Smirnov test.
- It is one of the non parametric test.
- This test is the equality of continuous one dimensional probability distribution.
- It can be used to compare sample with a reference probability distribution or to compare two samples.
- This test statistic measures a distance between the empirical distribution function of the sample and the cumulative distribution function of the reference distribution, or between the empirical distribution functions of two samples.
- The two-sample KS test is one of the most useful and general nonparametric methods for comparing two samples.
- It is sensitive to differences in both location and shape of the empirical cumulative distribution functions of the two samples.
- This test can be modified to serve as a goodness of fit test.
- The assumption of the KS test is:
- Null Hypothesis(H0):The sampled population is normally distributed.
- Alternative hypothesis(Ha):The sampled population is not normally distributed.
- The Kolmogorov-Smirnov test to compare a data set to a given theoretical distribution is as follows:
- 1.Data set sorted into increasing order and denoted as , where i=1,...,n.
- 2.Smallest empirical estimate of fraction of points falling below , and computed as for i=1,...,n.
- 3.Largest empirical estimate of fraction of points falling below and computed as for i=1,...,n.
- 4.Theoretical estimate of fraction of points falling below and computed as , where F(x) is the theoretical distribution function being tested.
- 5.Find the absolute value of difference of Smallest and largest empirical value with the theoretical estimation of points.
- This is a measure of "error" for this data point.
- 6.From the largest error, we can compute the test statistic.
- The Kolmogorov-Smirnov test statistic for the cumulative distribution F(x) is:where is the supremum of the set of distances.
- is the empirical distribution function for n,with the observations is defined as:where is the indicator function, equal to 1 if and equal to 0 otherwise.
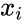 , where i=1,...,n.
, where i=1,...,n.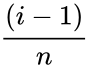 for i=1,...,n.
for i=1,...,n.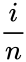 for i=1,...,n.
for i=1,...,n.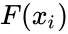 , where F(x) is the theoretical distribution function being tested.
, where F(x) is the theoretical distribution function being tested.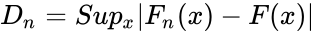 where
where 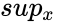 is the supremum of the set of distances.
is the supremum of the set of distances.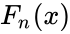 is the empirical distribution function for n,with the observations
is the empirical distribution function for n,with the observations 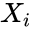 is defined as:
is defined as: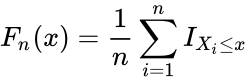 where
where 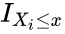 is the indicator function, equal to 1 if
is the indicator function, equal to 1 if 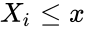 and equal to 0 otherwise.
and equal to 0 otherwise.Example
| A | B | |
|---|---|---|
| 1 | 15 | 20 |
| 2 | 17 | 14 |
| 3 | 19 | 16 |
| 4 | 21 | 25 |
| 5 | 23 | 27 |
- =KSTESTNORMAL(A1:A5,B1:B5,19,3.16)
| DATA | OBSERVED FREQUENCY | CUMULATIVE OBSERVED FREQUENCY | SN | Z-SCORE | F(X) | DIFFERENCE |
|---|---|---|---|---|---|---|
| 15 | 20 | 20 | 0.19608 | -0.74915 | 0.22688 | 0.03081 |
| 17 | 14 | 34 | 0.33333 | -0.07293 | 0.47093 | 0.1376 |
| 19 | 16 | 50 | 0.4902 | 0.6033 | 0.72684 | 0.23665 |
| 21 | 25 | 75 | 0.73529 | 1.27952 | 0.89964 | 0.16435 |
| 23 | 27 | 102 | 1 | 1.95574 | 0.97475 | 0.02525 |
| ANALYSIS | |
|---|---|
| MEAN | 17.21569 |
| STANDARDDEVIATION | 2.95761 |
| COUNT | 5 |
| D | 0.23665 |
| D-CRITICAL | #ERROR |
KS TEST TYPE NORMALDIST
- CONCLUSION - THE DATA IS NOT A GOOD FIT WITH THE DISTRIBUTION.
Related Videos
See Also
References