Manuals/calci/BARCHART
Jump to navigation
Jump to search
BARCHART (Data,DisplayElement,Options)
- is the set of values.
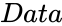 is the set of values.
is the set of values.Description
- This function shows the Bar graph for the given values.
- Bar Chart is also called Bar Graph.It represents the grouped data with rectangular bars with heights or lengths proportional to the values that they represent.
- A vertical bar chart is also named as Line Graph.
- It is also used for more complex comparisons of data with grouped bar charts and stacked bar charts.
- A bar Graph is considering the comparisons among discrete categories.
- One axis of the chart shows the specific categories being compared, and the other axis represents a measured value.
- Some bar graphs present bars clustered in groups of more than one, showing the values of more than one measured variable.
Example
| Sports | Boys | Girls |
|---|---|---|
| Basket Ball | 15 | 10 |
| Volley Ball | 15 | 15 |
| Badminton | 10 | 10 |
| Hand Ball | 20 | 10 |
- BARCHART(#TABLE1!A1:C5)
